Lexicon
![]() —-
—-

Breya: Why are all these metal… things… ignoring us?
‘The Voice’: Every age it seems, is tainted by the greed of men…
Navigation
-
What is it
-
White papers, white papers..Blood & Tears
-
The Story
-
What are the advantages?
-
Usage
-
Videos
-
Individual Repos
-
Dependencies
-
Issues
-
Lisence
-
Acknowledgement
-
Support
What is it? ⏎
LEXICON is a collection of high level javascript libraries to create interactive and synchronizable graphs and dashboards. I am updating these pages slowly.
White papers, white papers..Blood & Tears ⏎
Below is a list of publications that contributed to this project.
DEOGEN2: About a year old project. It is a machine learning based prediction software for human mutations. We used about half of the visualization modules here for this project (A.K.A Mutaframe):
- https://academic.oup.com/nar/article/45/W1/W201/3819233
I-PV: 4-5 year old project. Circular visualization that combines vanilla Javascript, D3 and Circos. Perhaps it is one of the largest project built with D3. Not the best coding quality but unique for sure. You think I am wrong? Submit me a challenger and I will post it here. Seriously.
- https://www.ncbi.nlm.nih.gov/pubmed/26454277
Indoril: 2 year old project. One of the first svg based 3D rendering modules built on top of I-PV. You think other tools does this already (filter variants && map them && renormalize scores && format based on amino acid && brush through domains && render)? Submit me a link with a similar project and its outcome and I will post it RIGHT here.
- https://www.biorxiv.org/content/early/2017/06/09/148122
The Story ⏎
About a year ago I started working on the Mutaframe project where we developed a data-visualization platform for all variants of the Human Genome:
- more then 30 000 proteins
- approximately 8000 points mutations for each protein
We tried concepts that has not been tried in bioinformatics such as:
- dedicated visualizations for submitting mutations for medical doctors & researchers
- displaying all variants at once from a protein and looking at AUC
- JS visualization components that can be synchronized with each other (I am not talking about a chart update, neither plain transform of one g group/svg with some gesture.)
To be able to do these, I needed components that can exactly do what I want. So I wrote a whole library of components from scratch using vanilla JS and D3:
There are currently 8 libraries (components or whatever you want to call them). Each has or will have their own repository & Gists:
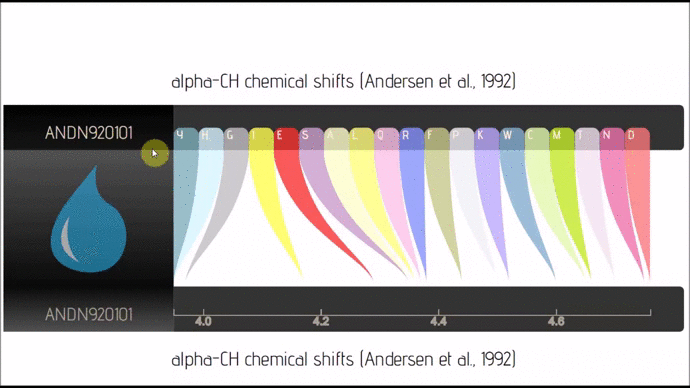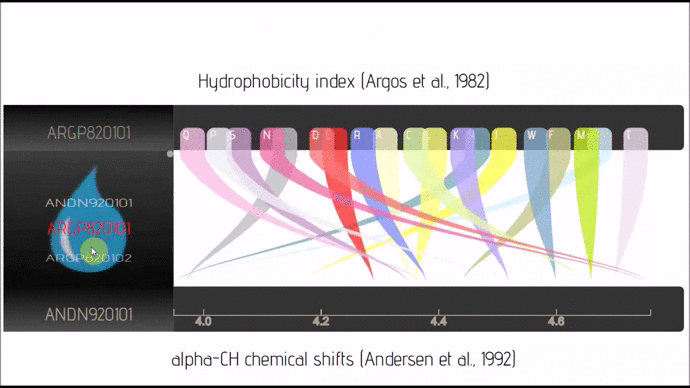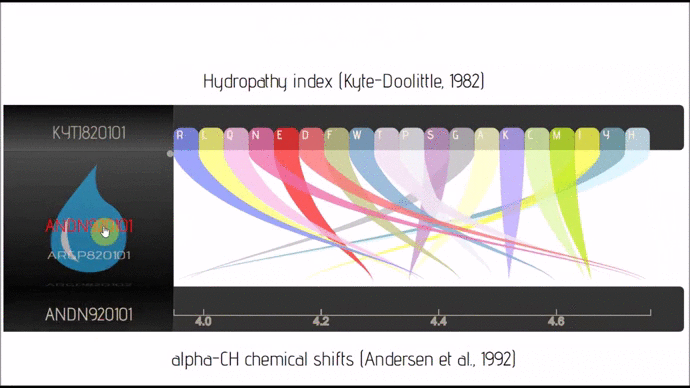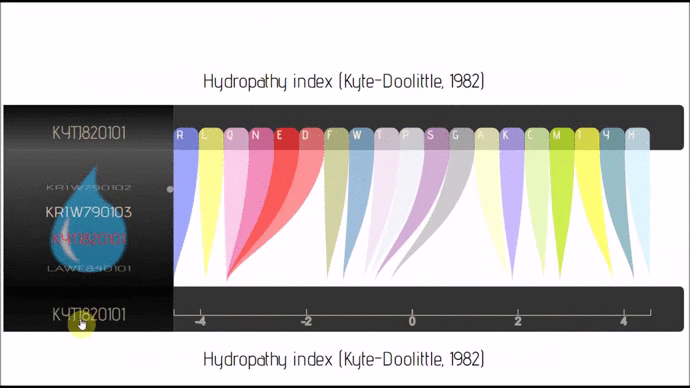
- lexicon-rainbow (Github; 🔍) :: Parallel Coordinates/Sankey with business logic embedded in JSON only.
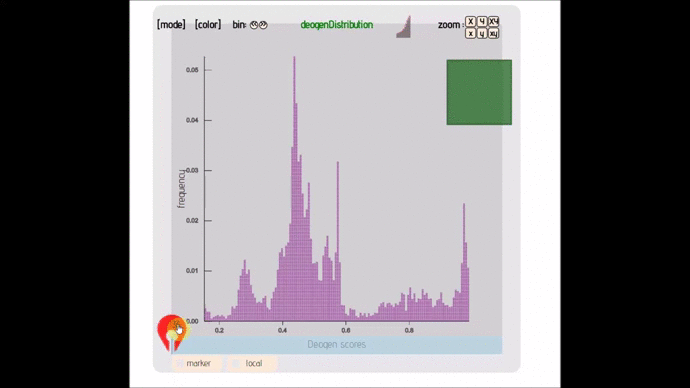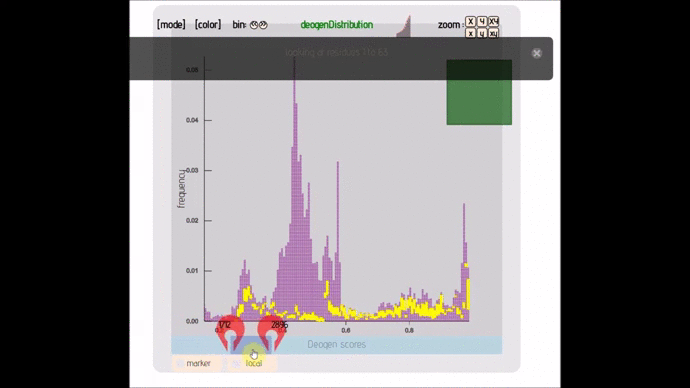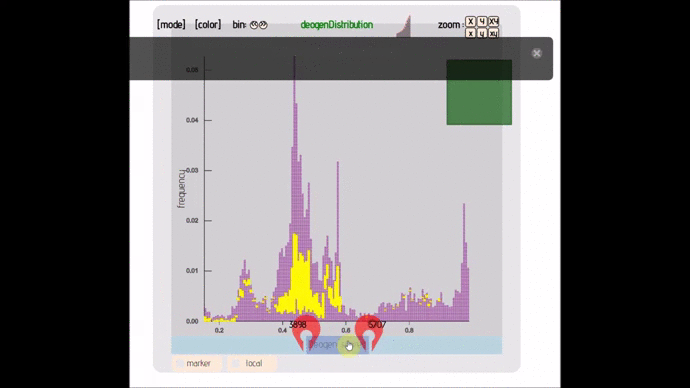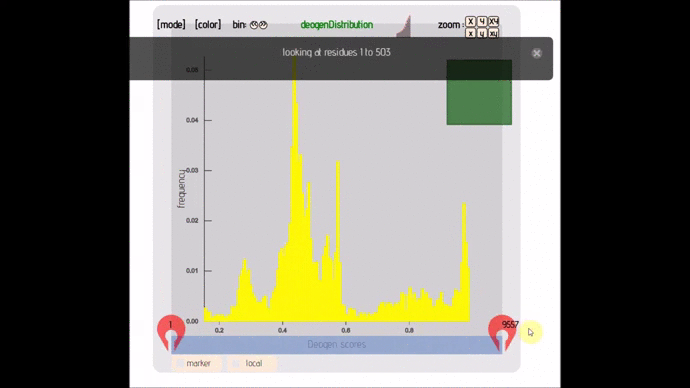
- lexicon-distribute (; 🔍) :: Distribution graph that allows you to change bin size, see individual points and AUC. Can handle up to 50 000 points.
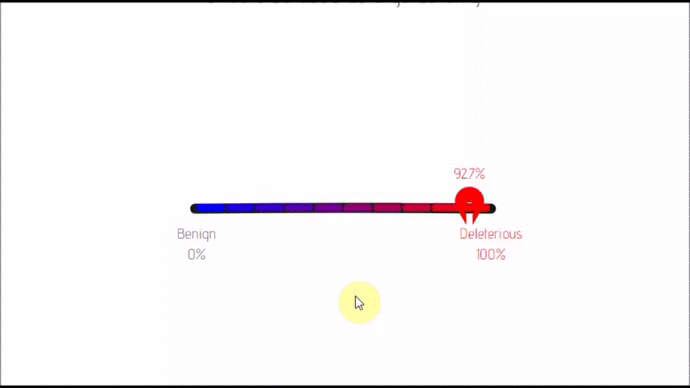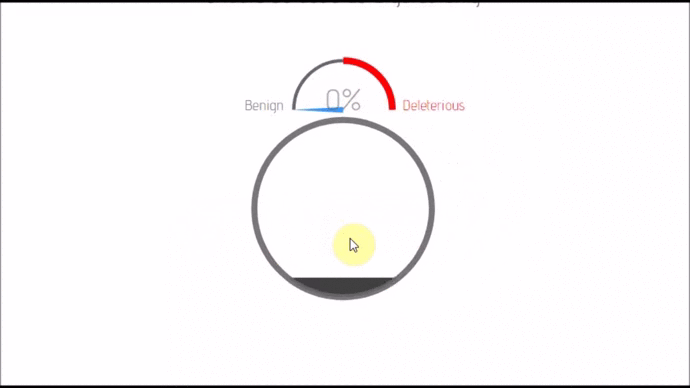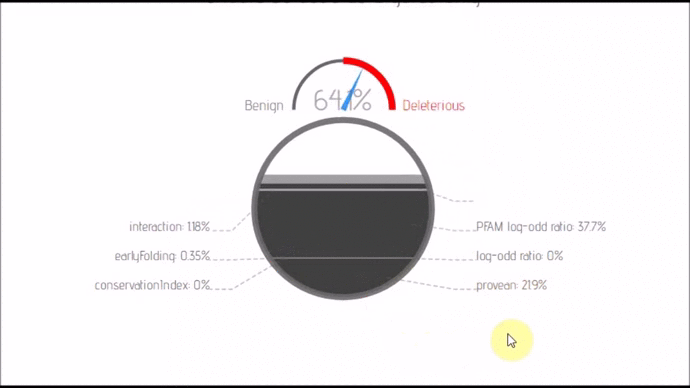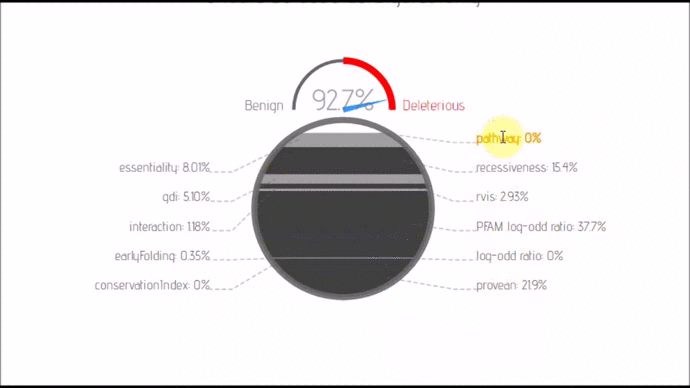
- lexicon-dash(; 🔍) :: Dash board that can transfrom between 2 layouts. Comes with nify and automatic label placement.


-
lexicon-plot(; 🔍) :: Similar to lexicon seq but instead it plots a line graph with bin options and other transforms
-
lexicon-ss(;🔍) :: A dedicated lexicon-plot version for protein secondary structure
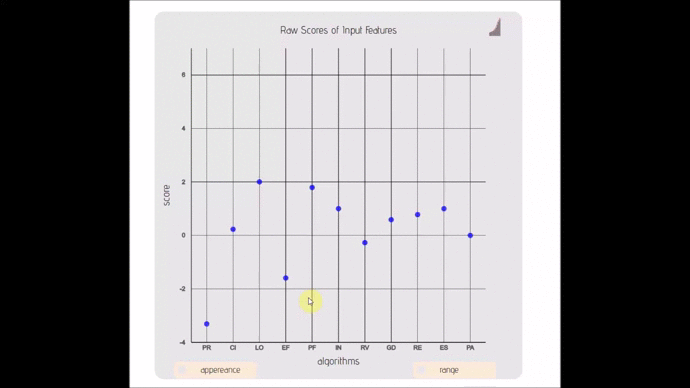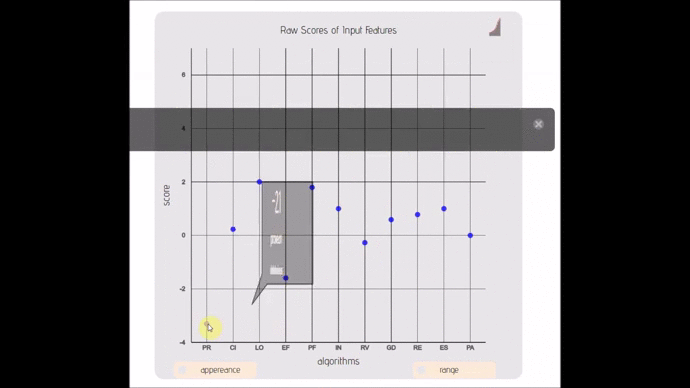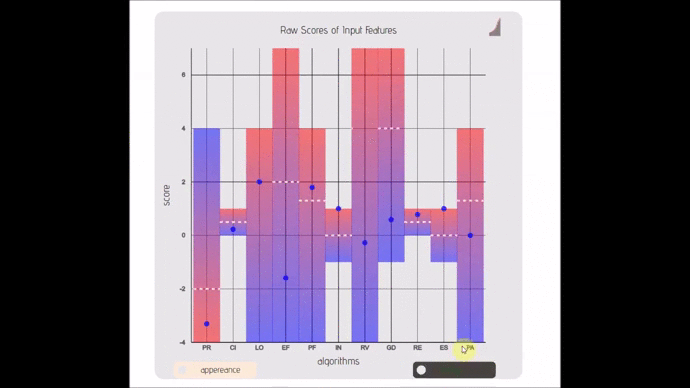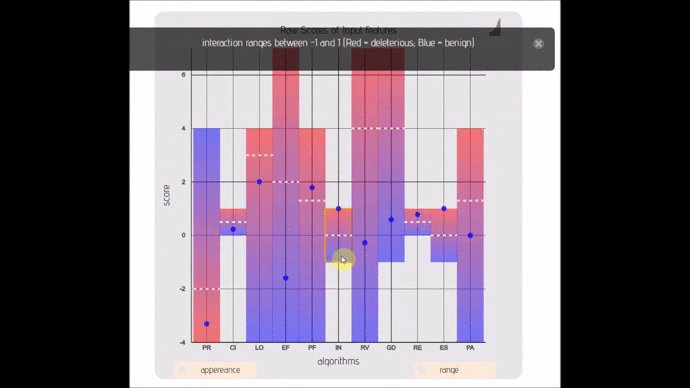
- lexicon-simplex(; 🔍) :: Strippted down version of a ordinal bar/scatter plot with adjustable ranges.
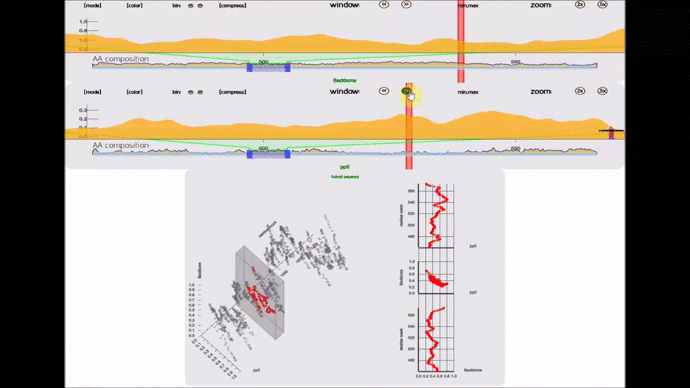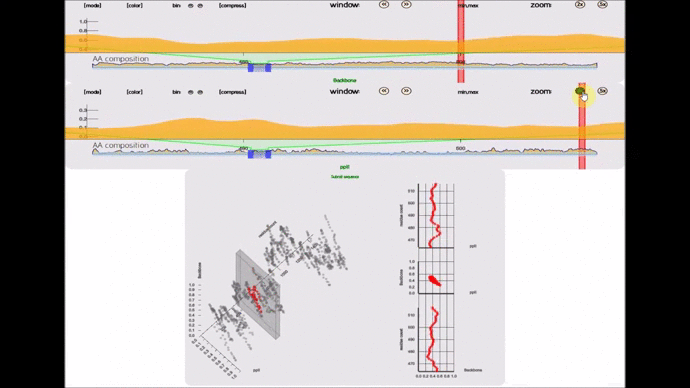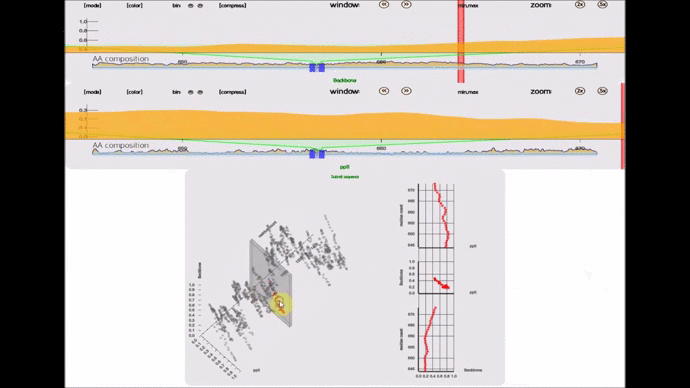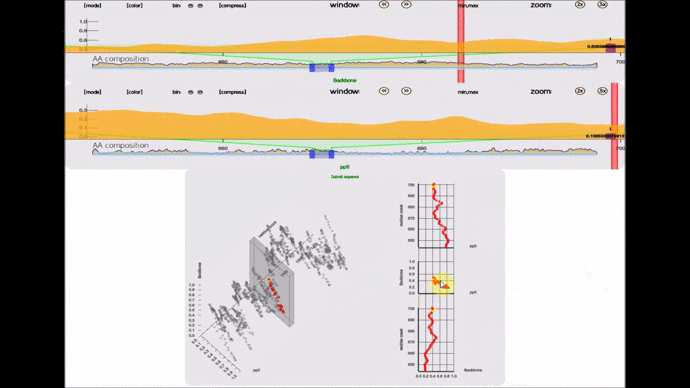
- lexicon-compare(; 🔍) :: A 3D perspective plot that compares 2 lexicon instances. Beware that this is not a 3D renderer. If you are looking for one in pure SVG, I have written one 2.5 years ago for this project and in this whitepaper.
What are the advantages? ⏎
- Lexicon libraries are old school. Drop the script tag and you are good to go. Some of the libraries like lexicon-rainbow are wrapped inside UMD. If you are also looking for an old school module manager, try taskq and help me make it better :)
- You can synchronize some of the modules with each other allowing you to build complex applications.
- Dependencies ? D3 and good old vanilla ‘Rex’ ES5. What else ? NONE.
- Instances have their methods privately. I rarely use the prototype. JS engines are changing fast. At the time I started lexicon, access to private methods were faster. So as a result:
- current libraries are not the most memory efficient but they should be fast. (And it is very very very unlikely that the bottle neck will be the extra few bytes from methods of multiple instances. Probably it will be your beloved DOM nodes, as always.)
- I might rewrite a more prototype reliant version depending on the JS engines (chrome especially)
Usage ⏎
Add the correspoding script tag (look for the .js files either in the dev folder or beta folder) to your html file. For usage, refer to the individual repository for the module you liked (if exists at the moment). Or take a look at the gists if possible.
Videos ⏎
I ocasionally upload videos to illustrate use cases. Those who are coming from white paper references, below is a link that shows how you can try synchronible lexicon-modules (sorry for the voice, there was a problem with the microphone ☹ ):
Individual Repos ⏎
Below are the links to the individual repos:
If you cannot find the module above, then look inside the dev folder in this repository. If you also happen to find a version inside the beta folder, I strongly suggest you use that.
Dependencies ⏎
- Lexicon is written in Javascript (ES5) and D3.
- Unless the version of d3 is explicitly specified in the name of the module (example) assume that it is the latest release of D3v3 (3.5.17).
Issues ⏎
18/12/2017
</hr>
lexicon-distribute
- For synchronible plots, I suggest you use the beta version
- When you mouse over single elements the label will trigger mouseout. I might use node.contains or event.relatedTarget check to ignore mouse out. I will fix that in the next patch.
- ie 9 does not show the Joystic to reset, at least that’s what some people told me. I might reconsider moving it to the right all together.
- There are some performance issues when the node count is > 20000. I have some ideas at hand. Expect some nifty updates.
lexicon-seq
- I realized I have re-bound the data within the render function to the selection rather than storing the selection it self (eventhough the D3 version is v3 and selections silently update after enter unlike v4). I cannot quite recall why I did that. Rule #1: ‘Do no harm’. So I will modify those parts once I’m sure it’s not gonna break anything.
Lisence ⏎
Lisenced under GPL for Academic or Non-profit use only. It is dual licensed for commercial applications. Certain components have registered IP property rights, contact me if you have questions.
Acknowledgement ⏎
- Projects
- The Mutaframe (
 ) project, started in 2016 aims to be a visualization platform for mutations in human proteome (single nucleotide variants on coding regions of the human genome)
that is guided by machine learning. What was unique about the project is that, it’s not just about visualization of any data, it is related to healthcare. Several tools that is developed during this project (including this one) can also be used for generic purpose.
I will document and release these tools as I sieze the opportunity.
) project, started in 2016 aims to be a visualization platform for mutations in human proteome (single nucleotide variants on coding regions of the human genome)
that is guided by machine learning. What was unique about the project is that, it’s not just about visualization of any data, it is related to healthcare. Several tools that is developed during this project (including this one) can also be used for generic purpose.
I will document and release these tools as I sieze the opportunity.
- The Mutaframe (
- Organizations


Support ⏎
Just a small reminder:
- I work under the Academic umbrella, it’s not always the easiest to promote the work when I have to do several other things.
- I am not backed up by some ‘firm’ or some big whale ‘name’.
- Therefore I don’t have xk followers on Twitter.
- Consequently not a lot of people can hear about the project, nor support it.
- I don’t like bandwagon, and I suspect bandwagon has similar sentiments.
- I believe data visualization should be much more than just copying/pasting code and making small modifications.
- I see people extending already existing components and adding glue code around and then promote it as a framework—> I think we should go back to basics, an optimally low level and try get the best out of existing SVG spec etc.
- Above is a time consuming process.
So if you would like to show your support for this project you can contribute to my general PATREON page.
You cannot? It’s ok. Do you find it useful? Then please consider starring this repository -> motivation does not hurt.
Thank You!
Ibrahim Tanyalcin PhD